Spark. Быстрый старт
Spark - это аналитический движок для крупномасштабной обработки данных. Предоставляет быструю и универсальную платформу для обработки данных. Hadoop Spark ускоряет работу программ в памяти более чем в 100 раз, а на диске – более чем в 10 раз.
Для открытия оболочки Spark введите в команду:
$spark-shell
С помощью
spark-shell можно работать с уже существующими базами данных.Пример Select-запроса к ранее созданной таблице:
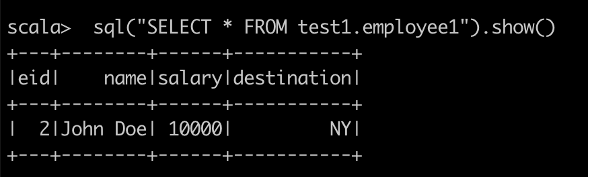
Увеличить
Преобразования RDD
RDD – это разновидность датасета (простого набора данных), который разделён на множество машин, работающих в кластере.
Ниже приведен список преобразований RDD.
Действия RDD
Ниже приведен список действий RDD.
Числовые операции RDD
Spark позволяет выполнять различные операции с числовыми данными, используя один из предопределенных методов API. Числовые операции Spark реализованы с помощью алгоритма потоковой передачи, который позволяет строить модель по одному элементу за раз. Эти операции вычисляются и возвращаются как объект
StatusCounter путем вызова метода status(). Ниже приводится числовых методов, доступных в StatusCounter.Spark-submit - это программа для отправки заданий Spark или PySpark для обработки на кластер Spark.
Простейшим примером использования
spark-submit является выполнение тестового скрипта, который вычисляет число π с указанной точностью:spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --num-executors 1 \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ <path_to_spark>/examples/jars/spark-examples.jar 10
Результатом работы запроса является строка:

Увеличить
В состав дистрибутива SDP Hadoop входят 2 версии Spark: Spark2 и Spark3.
При исполнении команды
spark-shell по умолчанию запускается Spark2. Для использования Spark3 необходимо явно указать версию перед вызовом нужной команды:SPARK_MAJOR_VERSION=3 spark-shell
или
SPARK_MAJOR_VERSION=3 spark-submit <params>