Hive. Быстрый старт
Hive – это система управления базами данных на основе платформы Hadoop. Она позволяет выполнять запросы, агрегировать и анализировать данные, хранящиеся в Hadoop.
Для работы с Hive рекомендуем воспользоваться утилитой beeline.
Для этого на любой машине в hadoop-кластере с установленным Hive достаточно набрать следующую команду:
$beeline -u "<jdbc url for hive>"
Значение
<jdbc url for hive> можно найти в Ambari вашего кластера на вкладке /Services/Hive/Summary.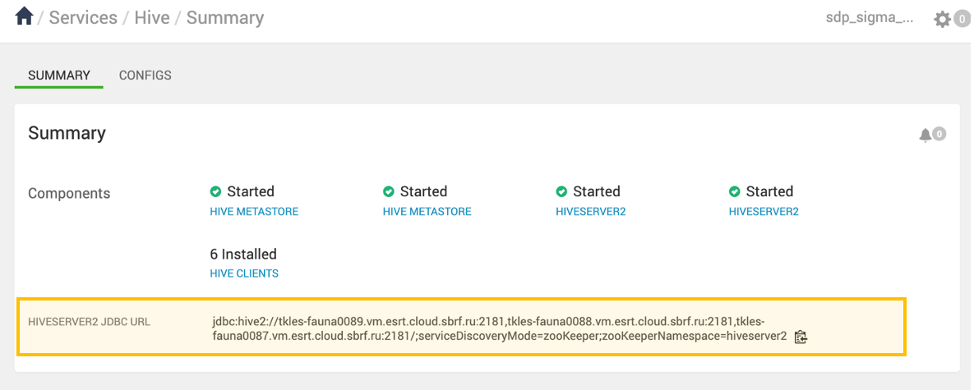
Увеличить
Просмотр доступных БД
Чтобы увидеть доступные базы данных, нужно воспользоваться командой:
SHOW DATABASES;
Создание новой БД
Чтобы создать новую базу данных, используйте следующую команду:
CREATE DATABASE IF NOT EXISTS <database name>;
Значение
<name database> может быть любое, но не должно пересекаться с существующими именами.Создание таблицы
Для того, чтобы создать таблицу в базе данных:
-
Выберите желаемую базу данных (
<name database>- имя существующей базы данных):USE <database name>; -
Создайте тестовую таблицу в выбранной базе данных:Пример type=sh
CREATE TABLE IF NOT EXISTS employee1 ( eid int, name String, salary String, destination String) COMMENT ‘Employee details’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE;Описание параметров:
Добавление данных в таблицу
Для добавления данных в таблицу используйте следующую команду:
INSERT INTO TABLE <table_name> VALUES (<add values as per column entity>);
INSERT INTO TABLE test1.employee1 VALUES (2, 'John Doe', '10000', 'NY');
Проверить корректность добавления данных в таблицу можно следующим запросом:
SELECT \* FROM employee;
Удаление БД со всеми таблицами
Когда вы удаляете таблицу из Метастора Hive, она удаляет данные таблицы / столбца и их метаданные. Это может быть обычная (хранящаяся в Metastore) или внешняя таблица (хранящаяся в локальной файловой системе). Hive обрабатывает оба варианта одинаково, независимо от их типов, но при удалении внешних таблиц файлы не удаляются, их нужно удалять отдельными командами, например, командами HDFS.
DROP DATABASE [IF EXISTS] testdb [RESTRICT|CASCADE];
Загрузить файл можно при помощи команды:
hadoop fs -put
Загрузка данных в хранилище Hive
Пусть у пользователя в домашней папке на hdfs есть файл
sample.txt.sample.txt type=txt1 George 45000 Technical manager 2 Max 45000 Proof reader 3 Michel 40000 Technical writer 4 Kira 40000 Hr Admin 5 Kristin 30000 Op Admin
Загрузка данных выполняется при помощи следующей команды:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE INTO TABLE employee;
После запука команды данные будут перемещены из файла в хранилище Hive. Убедиться в этом можно, прочитав данные напрямую из хранилища:
hadoop fs -text /user/hive/warehouse/userdb.db/employee/* 1 George 45000 Technical manager 2 Max 45000 Proof reader 3 Michel 40000 Technical writer 4 Kira 40000 Hr Admin 5 Kristin 30000 Op Admin
Создание таблиц
Классические таблицы создаются через select-запросы к другим таблицам:
0: jdbc:hive2://tkles-fauna0089.vm.esrt.cloud> CREATE TABLE big_salary as SELECT * FROM employee WHERE salary > 40000; 0: jdbc:hive2://tkles-fauna0089.vm.esrt.cloud> SELECT * FROM big_salary; +-----------------+------------------+--------------------+-------------------------+--+ | big_salary.eid | big_salary.name | big_salary.salary | big_salary.destination | +-----------------+------------------+--------------------+-------------------------+--+ | 1 | George | 45000 | Technical manager | | 2 | Max | 45000 | Proof reader | +-----------------+------------------+--------------------+-------------------------+--+